
DINO:Self-Supervised Vision Transformer的新特性
发表于 2021-06-03 15:19
前段时间分享的MoCov3就是Self-Supervised和Transformer相结合的,但是DINO的结果更为惊艳。DINO主要有两点惊艳的新特性:
self-supervised ViT的features包含关于图像语义分割的明确信息。
这些features使用kNN分类器可以在ImageNet上达到78.3%的top-1精度。
先看一下DINO的特征可视化效果,orz
上图显示的是指定类别的响应图。这难道不是语义分割的标注吗???要知道self-supervised是不使用标注信息的无监督方法啊。
01
DINO
DINO整体结构如图所示。给定图片x,student和teacher两个分支输出k维概率分布的 和 ,概率P由softmax得到。
最小化student和teacher两个分支的输出,优化函数可以表示成:
其中 。
具体的,DINO给定一个图片,先产生不同views的集合V,这个结合包含了两个global views 和 ),和几个local(crop) views。所有crop的views只送入student分支,而global的views只送入teacher分支,这样可以让DINO学习到上下文关系。
于是优化函数可以表示成:
其中2个global views使用224的尺寸,而local views使用96的尺寸。teacher的参数 由student的参数 经过指数滑动平均得到,公式为 ,梯度更新的时候只更新student分支,teacher分支stop gradient。
网络结构g由backbone和projection head组成,其中projection head由3层MLP构成,最终得到K维的输出。当DINO使用ViT时,backbone和projection都是BN-free的。
Avoiding collapse
DINO通过一个centering和momentum teacher输出的sharpening来避免退化解。
用这种方法来避免退化解,可以减少对batch的依赖来增加稳定性:centering在一阶batch统计量中可以解释为给teacher增加一个bias项c: ,并且这个c通过指数滑动平均来更新,公式为:
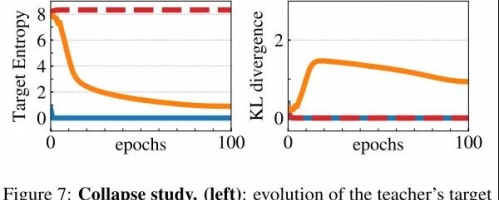
如左图所示,centering鼓励输出均匀分布,而sharpening鼓励输出的一个维度占主导地位。
KL散度为0表示出现退化解。当单独使用centering和sharpening时,DINO无法正常训练;当同时使用centering和sharpening时,随着训练epoch增加,KL散度先增大后减小,避免出现退化解。
总体流程如伪代码所示。
02
实验结果
最终实验结果中,DINO不管是相同架构下还是不同架构下,均大幅度超过之前的self-supervised方法,其中KNN分类器下最好能达到78.3,Linear分类器下最好能达到80.1,这是相当惊人的结果。
可视化
对比一下supervised和DINO可视化结果,可以看到DINO学出来的特征解释性更强,感觉就跟mask的标注一样,tql。
03
总结
从DINO对self-supervised+transformer的探索中可以看出,self-supervised的上限还有待进一步挖掘。
为什么DINO可以学习到解释性这么强的特征?
self-supervised+transformer的上限在哪里?
Reference
[1] Emerging Properties in Self-Supervised Vision Transformers

评论 (0人参与)
最新评论