
guava的bloom filter源码分析
发表于 2020-05-10 13:53
bloom filter简介
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。如果检测结果为是,该元素不一定在集合中;但如果检测结果为否,该元素一定不在集合中。因此Bloom filter具有100%的召回率。这样每个检测请求返回有“在集合内(可能错误)”和“不在集合内(绝对不在集合内)”两种情况,可见 Bloom filter 是牺牲了正确率和时间以节省空间。
所以他的应用场景很简单:一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
这篇博客对于bloom过滤器的理论推导有比较好的描述,大家可以移步去看看,本文就不再赘述了。
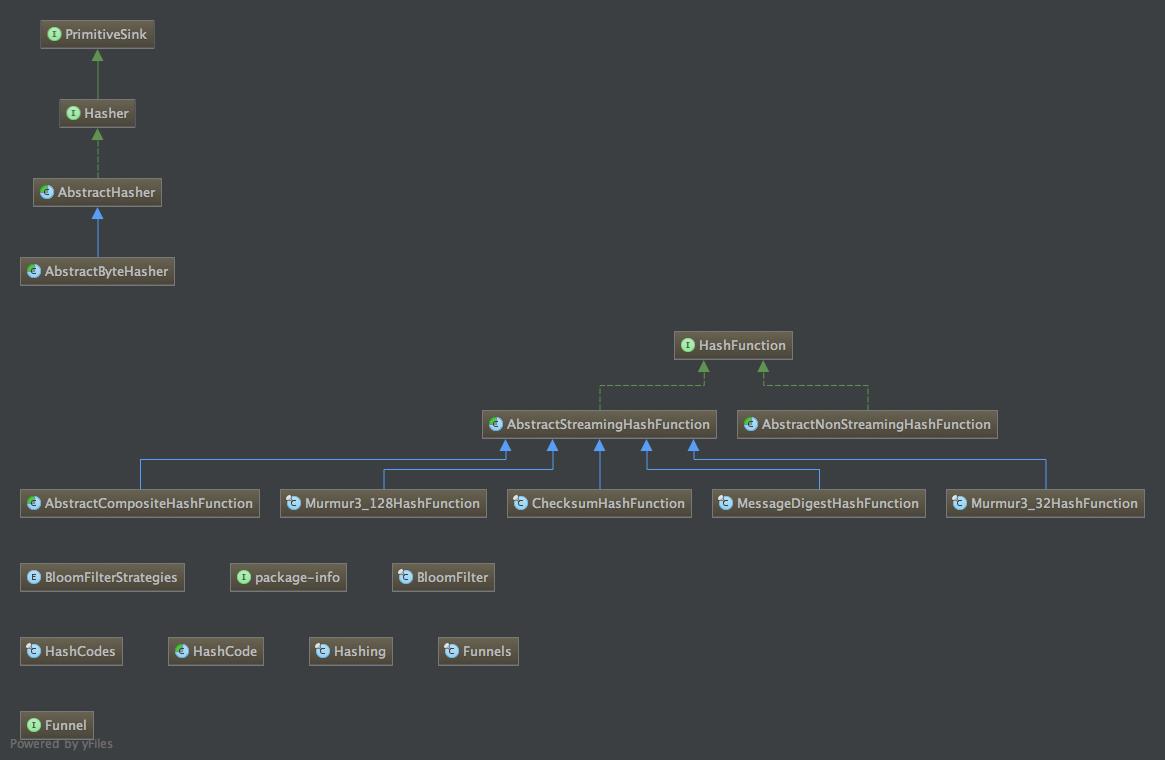
guava的bloom filter类图

入口类BloomFilter解析
//创建一个布隆过滤器 public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */, double fpp);
Funnel的作用在于,这个类会自动根据可能会做的插入操作的数量跟false positive(不懂看这里)的大小来自动创建一个布隆过滤器。注释中表明:如果你插入操作溢出了(比你指定的多),可能会导致false positive的严重退化。也就是说false positive会越来越大。这个类的详细说明在下述代码中:
@Beta
public final class BloomFilter<T> implements Predicate<T>, Serializable {
//bloom过滤器使用的位数组
private final BitArray bits;
//一个元素使用的hash函数的个数
private final int numHashFunctions;
//将类型T的对象转化为字节,主要用来做hash的key,说明Guava的BloomFilter可以针对任何可hash的对象来hash
private final Funnel<T> funnel;
//用于将一个元素T映射到bit索引上的策略,比如具体的hash策略
private final Strategy strategy;
//私有的构造函数,说明应该由工厂来创建
private BloomFilter(BitArray bits, int numHashFunctions, Funnel<T> funnel, Strategy strategy) {
this.bits = checkNotNull(bits);
this.numHashFunctions = numHashFunctions;
this.funnel = checkNotNull(funnel);
this.strategy = checkNotNull(strategy);
}
//查看是否包含这个对象,会将判断的操作代理给Strategy
public boolean mightContain(T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}
//将对象objecthash到的位置1
public boolean put(T object) {
return strategy.put(object, funnel, numHashFunctions, bits);
}
//写的这个求概率的函数貌似有点问题
public double expectedFpp() {
// You down with FPP? (Yeah you know me!) Who's down with FPP? (Every last homie!)
//看了上面这段注释我真感慨谷歌的程序员也是无聊屌丝一枚啊
return Math.pow((double) bits.bitCount() / bits.size(), numHashFunctions);
}
@Override
public int hashCode() {
return Objects.hashCode(numHashFunctions, funnel, strategy, bits);
}
//创建一个布隆过滤器
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */, double fpp) {
//根据fpp和n最大值类计算bit数组的大小
long numBits = optimalNumOfBits(expectedInsertions, fpp);
//bit数组的大小m和插入的个数的最大值n来计算hash函数的个数
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel, BloomFilterStrategies.MURMUR128_MITZ_32);
}
//默认FPP为0.03
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round(m / n * Math.log(2)));
}
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
}这个类使用了工厂模式来创建BloomFilter对象,使用代理模式将过滤器的操作代理给strategy对象,将对象序列化的操作代理给了funnel对象,上述计算中使用到的公式一览如下:
/* 公式一览,具体可以参见博客 * m: bit数组的大小 * n: 期望做hash的对象的个数 * b: m/n 比率 * p: 期望的false positive的概率 * * 1) Optimal k = b * ln2 * 2) p = (1 - e ^ (-kn/m))^k * 3) For optimal k: p = 2 ^ (-k) ~= 0.6185^b * 4) For optimal k: m = -nlnp / ((ln2) ^ 2) */
对象序列化
Funnel
对象的序列化是通过Funnel来完成的,我们看一下Funnel,之所以起名叫Funnel(漏斗)是因为可以将一个T类型的对象变成一个primitivesink(可下沉的元数据?)。由于布隆过滤器需要一个合理的Funnel来进行序列化,所以guava建议最好将所有的funnel实现成具有单个元素的枚举类型来确保成功序列化。并给出了一个示例,这种技巧在effective java第二版中有描述
public enum PersonFunnel implements Funnel<Person> {
INSTANCE;
public void funnel(Person person, PrimitiveSink into) {
into.putString(person.getFirstName())
.putString(person.getLastName())
.putInt(person.getAge());
}
}}这样就可以实现Funnel funnel = PersonFunnel.INSTANCE的写法,然后直接调用funnel.funnel(person, sink)即可,序列化后的值放到了PrimitiveSink中去了。所以我们来看一下PrimitiveSink的实现方法。在guava中实现了常见的原始类型的Funnel,在工厂类Funnels中。
PrimitiveSink
PrimitiveSink是用来接收一个元数据类型的流的接口类。他的所有的方法的可见性都是default,所以只能在当前package可访问。每一个方法返回类型都是PrimitiveSink,所以我们可以primitiveSink.putByte(b).putString("").putLong(0)这样使用。具体有哪些类实现了这个接口呢?看上面的类图有Hasher,AbstractHasher,AbstractByteHasher。Hasher类增加了几个方法:
//序列化一个object <T> Hasher putObject(T instance, Funnel<? super T> funnel); //计算这个对象序列化后的hash值 HashCode hash();
AbstractHasher没什么好说的;AbstractByteHasher主要作用在于处理将原始类型转换为字节数组之后,再讲所有的字节放到sink中并计算hash,里面维护了一个scratch来将原始类型转换为字节数组。
//创建一个8字节大小的字节缓冲区,字节在内存排列是低字节的(字节的低位在低地址,记不清的话google) private final ByteBuffer scratch = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN);
归根到底,PrimitiveSink对象将担任起将数据变成一个字节数组,再提供一些可以随时改变hash值的方法比如说update,如果现在还有些疑问的话可以先放一放,我们来看看类图中负责Hash的几个类HashFunction, AbstractStreamingFunction以及其子类。
Hash对象
HashFunction
首先我们来看看父类HashFunction,HashFunction是一个纯函数(pure function,下面会做解释)提供一个将一个随机出现的数据块(data block)映射成一个Hash code的方法,不同的数据块尽量映射到不同的hash值(collision-averse)。
看了上面对于HashFunction的解释肯定跟事先大家学的算法中的hash的概念有点出入,所以我们先看下guava给出的几个定义:
数据块(data block):hash函数的输入永远是一个数据块,概念上是一个排好序的字节数组。通常api会将这一个随机的字节序列转换成一个原生的字节序列。
hash code:一个hash函数通常会产出一个固定长度字节的hash值,比如说sha1会生成160位的数值,而murmur3_32会产出32位的数值,由于一个long型已经不能表示160位数据啦,所以使用一个类叫HashCode来表示hash值。
纯函数(pure function):HashFunction产生的hashcode必须只能跟数据块中字节,以及字节出现的顺序有关,HashFunction必须是无状态的,也就是说线程安全的。所以称HashFunction为纯函数。
collision-averse(避免冲突):这个大家都能理解,不同的data block要尽量映射到不同的HashCode,如果不是的话,那说明这个HashFunction很糟糕。
一个高质量的HashFunction必须往下面几个优雅的实践靠拢。
collision-resistant:坚决不能有冲突,这个每一个学计算机的人都知道;
bit-dispersing:hash出来的值在整个值域中尽量的分散开来;
cryptographic:尽量不能让逆向工程成功,给一个hash值不能被逆向工程得到被hash的值,具有一定加密性;
快:hash函数一定要非常快,太慢的hash函数就失去了他的意义了。
HashFunction主要的用来提供数据的是Hasher类,也就是上面的继承自PrimitiveSink的对象。获取一个Hasher对象可以使用HashFunction的newHasher方法。如果你只是想Hash一些元数据类型的数据,比如说long,int,byte或者String对象HashFunction对象中有现成的已经实现好的,比如说:
HashCode hashInt(int input); HashCode hashLong(long input); HashCode hashBytes(byte[] input); HashCode hashBytes(byte[] input, int off, int len); HashCode hashString(CharSequence input); HashCode hashString(CharSequence input, Charset charset);
总之HashFunction是一个接口,其定义了可以通过HashFunction获取一个放置可序列化对象的地方以及常见类型对象的Hash方法。并且规定了Hash值用HashCode来表示
HashCode
@Beta
public abstract class HashCode {
HashCode() {}
//讲一个HashCode变成一个对象类型的数据
public abstract int asInt();
public abstract long asLong();
public abstract long padToLong();
public abstract byte[] asBytes();
}HashCode是一个抽象类,我们选取工厂类HashCodes中的一个具体实现:BytesHashCode。我们惊奇的发现HashCode返回hashCode使用的是Object中的hashCode,也就是说HashCode的值域为0~2^32-1,那也就是说Guava的布隆过滤器只能映射2^32个值,为了确保较小的FPP,真正能使用的要小很多。具体的一个BytesHashCode实现如下:
private static final class BytesHashCode extends HashCode implements Serializable {
final byte[] bytes
// 变成一个int值,采用的方法是将低位的4个字节组合成一个int值,如果是long的话就讲低位的8字节
@Override public int asInt() {
checkState(bytes.length >= 4,
"HashCode#asInt() requires >= 4 bytes (it only has %s bytes).", bytes.length);
return (bytes[0] & 0xFF)
| ((bytes[1] & 0xFF) << 8)
| ((bytes[2] & 0xFF) << 16)
| ((bytes[3] & 0xFF) << 24);
}
//将一个字节数组映射成hashCode的方法
@Override
public int hashCode() {
if (bytes.length >= 4) {
//如果长度小于4,直接使用asInt()作为hash值
return asInt();
} else {
int val = (bytes[0] & 0xFF);
//否则的话就将第i个字节往左移动i*8位再与val做或运算
for (int i = 1; i < bytes.length; i++) {
val |= ((bytes[i] & 0xFF) << (i * 8));
}
return val;
}
}
}有了上面这几个类,我们来看一下HashFunction的一个具体的实现:MessageDigestHashFunction
MessageDigestHashFunction
//实现了一个适配器,适配器模式忘记的google之
final class MessageDigestHashFunction extends AbstractStreamingHashFunction
implements Serializable {
//信息摘要算法比如说SHA1,SHA256,记不清的google之
private final MessageDigest prototype = MessageDigest.getInstance(algorithmName, provider);
private final int bytes;
private final boolean supportsClone;
private final String toString;
@Override public Hasher newHasher() {
return new MessageDigestHasher((MessageDigest) prototype.clone(), bytes);
}
// Hasher对象,将所有的Hasher的操作代理给MessageDigest对象
private static final class MessageDigestHasher extends AbstractByteHasher {
private final MessageDigest digest;
private final int bytes;
private boolean done;
@Override
protected void update(byte b) {
checkNotDone();
//重写了update方法,其调用MessageDigest的update方法
digest.update(b);
}
@Override
protected void update(byte[] b) {
checkNotDone();
digest.update(b);
}
@Override
protected void update(byte[] b, int off, int len) {
checkNotDone();
digest.update(b, off, len);
}
@Override
public HashCode hash() {
done = true;
return (bytes == digest.getDigestLength())
//调用工厂方法的fromBytesNoCopy方法返回一个BytesHashCode对象,BytesHashCode对象的定义在HashCodes这个工厂类中
? HashCodes.fromBytesNoCopy(digest.digest())
: HashCodes.fromBytesNoCopy(Arrays.copyOf(digest.digest(), bytes));
}
}
}关于信息指纹SHA算法,大家可以移步到这里看一个SHA3的示例,google在chrome中已经慢慢弃用SHA1。MessageDigest大家可以参考jdk的源码。
至此整个布隆过滤器的源码结构就很清晰啦
总结
guava的布隆过滤器很灵活,hash的算法可以使用已经定义好的三个:MessageDigest,Murmur3_32以及Murmur3_128(算法的C++代码看这里),或者你自己扩展AbstractStreamingHashFunction任意定义Hash算法。Murmur3算法有一个种子,种子的不同hash出来的值也不一样。序列化使用了Funnel,并代理给一个Hasher,这个Hasher负责返回一个具体的HashCode,这个HashCode就是我们最后将一个对象映射到的Hash值,由于所有的hashCode方法都是返回的int,所以值域空间只有2^32,如果超过了恐怕另外想办法了。guava的布隆过滤器使用起来也很方便:
@Beta
public final class BloomFilter<T> implements Predicate<T>, Serializable {
//bloom过滤器使用的位数组
private final BitArray bits;
//一个元素使用的hash函数的个数
private final int numHashFunctions;
//将类型T的对象转化为字节,主要用来做hash的key,说明Guava的BloomFilter可以针对任何可hash的对象来hash
private final Funnel<T> funnel;
//用于将一个元素T映射到bit索引上的策略,比如具体的hash策略
private final Strategy strategy;
//私有的构造函数,说明应该由工厂来创建
private BloomFilter(BitArray bits, int numHashFunctions, Funnel<T> funnel, Strategy strategy) {
this.bits = checkNotNull(bits);
this.numHashFunctions = numHashFunctions;
this.funnel = checkNotNull(funnel);
this.strategy = checkNotNull(strategy);
}
//查看是否包含这个对象,会将判断的操作代理给Strategy
public boolean mightContain(T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}
//将对象objecthash到的位置1
public boolean put(T object) {
return strategy.put(object, funnel, numHashFunctions, bits);
}
//写的这个求概率的函数貌似有点问题
public double expectedFpp() {
// You down with FPP? (Yeah you know me!) Who's down with FPP? (Every last homie!)
//看了上面这段注释我真感慨谷歌的程序员也是无聊屌丝一枚啊
return Math.pow((double) bits.bitCount() / bits.size(), numHashFunctions);
}
@Override
public int hashCode() {
return Objects.hashCode(numHashFunctions, funnel, strategy, bits);
}
//创建一个布隆过滤器
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */, double fpp) {
//根据fpp和n最大值类计算bit数组的大小
long numBits = optimalNumOfBits(expectedInsertions, fpp);
//bit数组的大小m和插入的个数的最大值n来计算hash函数的个数
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel, BloomFilterStrategies.MURMUR128_MITZ_32);
}
//默认FPP为0.03
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round(m / n * Math.log(2)));
}
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
}执行结果
@Beta
public final class BloomFilter<T> implements Predicate<T>, Serializable {
//bloom过滤器使用的位数组
private final BitArray bits;
//一个元素使用的hash函数的个数
private final int numHashFunctions;
//将类型T的对象转化为字节,主要用来做hash的key,说明Guava的BloomFilter可以针对任何可hash的对象来hash
private final Funnel<T> funnel;
//用于将一个元素T映射到bit索引上的策略,比如具体的hash策略
private final Strategy strategy;
//私有的构造函数,说明应该由工厂来创建
private BloomFilter(BitArray bits, int numHashFunctions, Funnel<T> funnel, Strategy strategy) {
this.bits = checkNotNull(bits);
this.numHashFunctions = numHashFunctions;
this.funnel = checkNotNull(funnel);
this.strategy = checkNotNull(strategy);
}
//查看是否包含这个对象,会将判断的操作代理给Strategy
public boolean mightContain(T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}
//将对象objecthash到的位置1
public boolean put(T object) {
return strategy.put(object, funnel, numHashFunctions, bits);
}
//写的这个求概率的函数貌似有点问题
public double expectedFpp() {
// You down with FPP? (Yeah you know me!) Who's down with FPP? (Every last homie!)
//看了上面这段注释我真感慨谷歌的程序员也是无聊屌丝一枚啊
return Math.pow((double) bits.bitCount() / bits.size(), numHashFunctions);
}
@Override
public int hashCode() {
return Objects.hashCode(numHashFunctions, funnel, strategy, bits);
}
//创建一个布隆过滤器
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */, double fpp) {
//根据fpp和n最大值类计算bit数组的大小
long numBits = optimalNumOfBits(expectedInsertions, fpp);
//bit数组的大小m和插入的个数的最大值n来计算hash函数的个数
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel, BloomFilterStrategies.MURMUR128_MITZ_32);
}
//默认FPP为0.03
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round(m / n * Math.log(2)));
}
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
}这个默认创造出来的布隆过滤器使用的hash算法为MURMUR128,最后我们想知道guava是怎么实现k各hash函数的呢,其实很简单,他并没有实现k个hash函数,换了一种实现方案。我们看看Strategy枚举类的一个put实现方案:
@Beta
public final class BloomFilter<T> implements Predicate<T>, Serializable {
//bloom过滤器使用的位数组
private final BitArray bits;
//一个元素使用的hash函数的个数
private final int numHashFunctions;
//将类型T的对象转化为字节,主要用来做hash的key,说明Guava的BloomFilter可以针对任何可hash的对象来hash
private final Funnel<T> funnel;
//用于将一个元素T映射到bit索引上的策略,比如具体的hash策略
private final Strategy strategy;
//私有的构造函数,说明应该由工厂来创建
private BloomFilter(BitArray bits, int numHashFunctions, Funnel<T> funnel, Strategy strategy) {
this.bits = checkNotNull(bits);
this.numHashFunctions = numHashFunctions;
this.funnel = checkNotNull(funnel);
this.strategy = checkNotNull(strategy);
}
//查看是否包含这个对象,会将判断的操作代理给Strategy
public boolean mightContain(T object) {
return strategy.mightContain(object, funnel, numHashFunctions, bits);
}
//将对象objecthash到的位置1
public boolean put(T object) {
return strategy.put(object, funnel, numHashFunctions, bits);
}
//写的这个求概率的函数貌似有点问题
public double expectedFpp() {
// You down with FPP? (Yeah you know me!) Who's down with FPP? (Every last homie!)
//看了上面这段注释我真感慨谷歌的程序员也是无聊屌丝一枚啊
return Math.pow((double) bits.bitCount() / bits.size(), numHashFunctions);
}
@Override
public int hashCode() {
return Objects.hashCode(numHashFunctions, funnel, strategy, bits);
}
//创建一个布隆过滤器
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */, double fpp) {
//根据fpp和n最大值类计算bit数组的大小
long numBits = optimalNumOfBits(expectedInsertions, fpp);
//bit数组的大小m和插入的个数的最大值n来计算hash函数的个数
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
return new BloomFilter<T>(new BitArray(numBits), numHashFunctions, funnel, BloomFilterStrategies.MURMUR128_MITZ_32);
}
//默认FPP为0.03
public static <T> BloomFilter<T> create(Funnel<T> funnel, int expectedInsertions /* n */) {
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
@VisibleForTesting
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round(m / n * Math.log(2)));
}
@VisibleForTesting
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
}另外guava中使用的BitArray是自己定义的,他使用long[]数组来实现对某一位的set操作通过位运算完成,大家应该都懂的,具体可以参看BloomFilterStrategies.BitArray类的定义。
布隆过器介绍完毕。

评论 (1人参与)
最新评论
看起来好高端,厉害!